
تقریباً ۱۲,۰۰۰ کلید و گذرواژه معتبر API در مجموعه دادههای Common Crawl که برای آموزش مدلهای مختلف هوش مصنوعی استفاده میشود، کشف شده است.
سازمان غیرانتفاعی Common Crawl یک مخزن عظیم و متنباز از دادههای وب بسیار زیاد را نگهداری میکند که از سال ۲۰۰۸ جمعآوری شده و بهصورت رایگان در دسترس همگان قرار دارد.
به دلیل گستردگی این مجموعه داده، بسیاری از پروژههای هوش مصنوعی ممکن است حداقل تا حدی برای دادههای آموزشی هوش مصنوعی و آموزش مدلهای زبانی بزرگ (LLM) به این آرشیو دیجیتال متکی باشند. شرکتهایی مانند OpenAI، DeepSeek، گوگل، متا، Anthropic و Stability از جمله استفادهکنندگان این مجموعه داده هستند.
کلیدهای روت AWS و کلیدهای APIمربوط به MailChimp در دادههای آموزشی هوش مصنوعی
محققان شرکت Truffle Security، که توسعهدهنده ابزار TruffleHog برای اسکن دادههای حساس است، با بررسی ۴۰۰ ترابایت داده از ۲.۶۷ میلیارد صفحه وب در آرشیو دسامبر ۲۰۲۴ سازمان Common Crawl، این اطلاعات حساس را کشف کردند.
آنها دریافتند که ۱۱,۹۰۸ کلید و گذرواژه افشا شده هنوز معتبر و قابل استفاده هستند. این موارد اغلب توسط توسعهدهندگان در کدهایشان بهصورت هاردکد شده قرار گرفتهاند، که نشاندهنده احتمال آموزش مدلهای LLM با کدهای ناایمن است.
در تحقیق انجامشده، فقط کلیدها و گذرواژههای فعال (Live Secrets) گزارش شدهاند. این موارد شامل کلیدهای API، گذرواژهها و سایر اطلاعات احراز هویت هستند که با سرویسهای مربوطه بهطور موفقیتآمیز تأیید شدهاند. با وجود اینکه هزاران کلید و گذرواژه معتبر شناسایی شد، تعداد رشتههایی که ظاهراً شبیه به کلیدهای حساس هستند اما تأیید نشدهاند، بسیار بیشتر است.
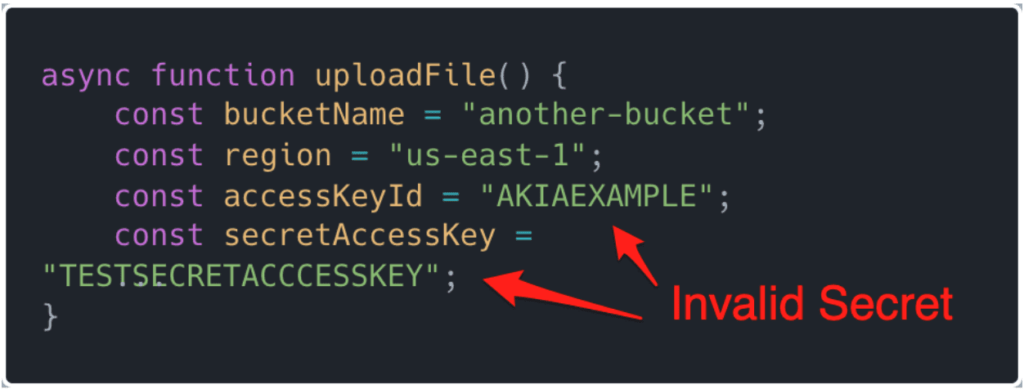
از سوی دیگر، مدلهای زبان بزرگ (LLM) در مرحله آموزش قادر به تشخیص بین کلیدهای معتبر و نامعتبر نیستند. این بدان معناست که هم کلیدهای واقعی و هم نمونههای نادرست در دادههای آموزشی، به یک اندازه در شکلگیری الگوهای ناامن در تولید کد تأثیر میگذارند. گرچه دادههای آموزشی مدلهای زبانی بزرگ قبل از پردازش اولیه فیلتر و پاکسازی میشوند تا اطلاعات نامرتبط، تکراری، مضر یا حساس حذف شوند؛ اما همچنان احتمال باقی ماندن دادههای محرمانه وجود دارد. این فرآیند هیچ تضمینی برای حذف کامل اطلاعات شناسایی شخصی(PII)، دادههای مالی، سوابق پزشکی و سایر اطلاعات حساس ارائه نمیدهد.
تحلیل دادههای اسکن شده نشان داد که کلیدهای API معتبر مربوط به خدمات Amazon Web Services (AWS) ،MailChimp و WalkScore در این مجموعه وجود دارد.

در مجموع، ابزار TruffleHog موفق به شناسایی ۲۱۹ نوع مختلف از دادههای حساس در مجموعه دیتای Common Crawl شد، که رایجترین آنها کلیدهای API مربوط به MailChimp بود.
طبق یافتههای محققان، تقریباً ۱,۵۰۰ کلید API مربوط به MailChimp به صورت هاردکد شده در کدهای HTML و JavaScript قسمت فرانتاند قرار داشتند. این اشتباه به این دلیل رخ داده که توسعهدهندگان بهجای استفاده از متغیرهای محیطی در سمت سرور، این کلیدها را مستقیماً در کدهای سمت کاربر قرار دادهاند.
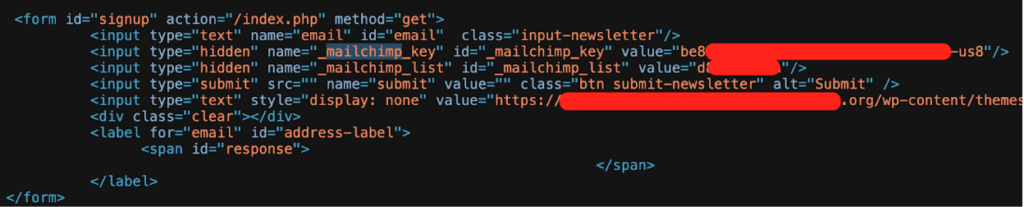
افشای این کلیدها میتواند توسط مهاجمان برای انجام حملات فیشینگ و جعل برندها مورد سوءاستفاده قرار گیرد. علاوه بر این، دسترسی غیرمجاز به این کلیدها میتواند منجر به سرقت دادهها شود.
یکی دیگر از نکات قابل توجه، نرخ بالای استفاده مجدد از کلیدهای کشفشده بود. درواقع، ۶۳٪ از کلیدهای افشا شده در چندین صفحه تکرار شده بودند. بهعنوان نمونه، یک کلید API مربوط به WalkScore بیش از ۵۷,۰۲۹ بار در ۱,۸۷۱ زیردامنه مختلف مشاهده شد.
همچنین، محققان یک صفحه وب را پیدا کردند که حاوی ۱۷ وبهوک زنده مربوط به نرم افزار Slack بود. این وبهوکها باید کاملاً محرمانه بمانند، زیرا میتوانند به برنامهها اجازه دهند پیامهایی را مستقیماً در فضای Slack ارسال کنند. شرکت Slack نیز هشدار داده که نباید این وبهوکها را بهصورت عمومی در مخازن کد منتشر کرد.
اقدامات پس از افشا
پس از انجام این تحقیق، شرکت Truffle Security با ارائهدهندگان خدمات آسیبدیده تماس گرفته و به آنها کمک کرد تا کلیدهای API کاربران خود را باطل کنند. این شرکت موفق شد چندین هزار کلید را بههمراه این سازمانها غیرفعال و جایگزین کند.
هشدار به شرکتهای فعال در حوزه هوش مصنوعی
حتی اگر یک مدل هوش مصنوعی از آرشیوهای قدیمیتر نسبت به دادههای بررسیشده استفاده کند، یافتههای Truffle Security نشان میدهد که شیوه کدنویسی ناایمن میتواند بر عملکرد مدلهای زبانی بزرگ تأثیر بگذارد.
بهبود تنظیمات امنیتی و ایجاد مکانیزمهای حفاظتی قوی تر در مدلهای زبانی بزرگ می تواند به کاهش خطر تولید ناخواسته یا افشای اطلاعات حساس کمک کند. یکی از رویکردهای احتمالی برای افزایش ایمنی این مدلها، استفاده از تکنیکهایی مانند هوش مصنوعی قانونمحور (Constitutional AI) است.