
تحقیقات اخیر، پیشرفتهای هشدار دهندهای را در استفاده از هوش مصنوعی (AI) برای تولید بدافزار با قابلیت تولید ۱۰,۰۰۰ نوع جدید کد مخرب نشان داده است که در 88 درصد موارد قادر به دور زدن مکانیزمهای امنیتی و شناسایی هستند. این پیشرفت، تغییر قابل توجهی را در چشم انداز تهدیدات امنیت سایبری نشان میدهد.
کارشناسان امنیت سایبری Palo Alto Networks نشان دادهاند که مدلهای زبانی بزرگ (LLM) میتوانند بدافزارهای موجود، به ویژه کدهای جاوا اسکریپت را بهطور مؤثر بازنویسی کنند تا انواع جدیدی ایجاد نمایند که عملکرد مخرب خود را حفظ میکنند و در عین حال تمیز و فاقد کد مخرب به نظر میرسند.
این امر از طریق تغییر شکلهای مختلف مانند تغییر نام متغیرها، تقسیم رشته، درج کد، حذف فضاهای خالی غیر ضروری و پیادهسازی مجدد کد انجام میشود که عملکرد سیستمهای تشخیص بدافزار سنتی را به میزان قابل توجهی کاهش میدهد.
انواع کدهای تولید شده با هوش مصنوعی از تکنیکهای مبهم سازی پیچیده استفاده میکنند. مبهمسازی کد توسط LLM در مقایسه با کتابخانههای مبهمسازی سنتی (مانند obfuscator.io) طبیعیتر میباشند که تشخیص آنها را توسط ابزارهای امنیتی، از جمله پلتفرمهایی مانند VirusTotal سختتر و چالش برانگیزتر میکند.
مطالعات نشان داده است که VirusTotal تنها 12 درصد از این نمونههای تولید شده توسط هوش مصنوعی را به عنوان کد مخرب علامتگذاری کرده است!
بدافزار تولید شده همچنین ویژگیهای چند شکلی را از خود نشان میدهد، به این معنا که میتواند کد خود را با هر بار تکرار تغییر دهد و تلاشهای شناسایی را پیچیده کند. این سازگاری به آن اجازه میدهد تا از روشهای تشخیص مبتنی بر امضا که به طور فزایندهای در برابر چنین تهدیدهای پویایی بی اثر میشوند، فرار کند.
از سوی دیگر، ابزارهایی مانند WormGPT برای خودکارسازی ایجاد ایمیلهای فیشینگ و تولید بدافزار پدید آمدهاند که نقش رو به رشد هوش مصنوعی مولد را در جرایم سایبری برجسته میکنند.
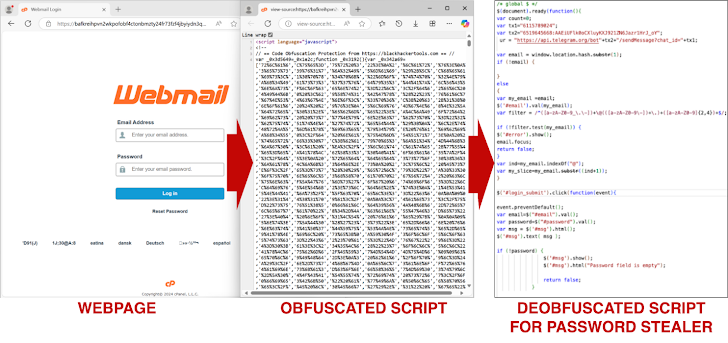
LLM قادر به بازنویسی مکرر نمونههای بدافزار موجود با هدف کنار گذاشتن تشخیص توسط مدلهای یادگیری ماشین (ML) مانند Innocent Until Proven Guilty (IUPG) یا PhishingJS است و به طور موثر راه را برای ایجاد 10000 نمونه جاوا اسکریپت جدید هموار میکند.
حمله TPUXtract به TPUهای Google Edge
در همین حال، تهدیدات امنیت سایبری به سختافزار نیز گسترش یافته است، به طوری که محققان دانشگاه ایالتی کارولینای شمالی از یک حمله کانال جانبی به نام TPUXtract که واحدهای پردازش تنسور Google Edge را هدف قرار میدهد، خبر دادند. واحد پردازشی تنسور (TPU[1]) یک مدارهای مجتمع با کاربرد خاص است که بهطور خاص برای یادگیری ماشین توسط گوگل طراحی شده است.
مکانیزم TPUXtract با گرفتن سیگنالهای الکترومغناطیسی (EM) منتشر شده توسط TPU در طول استنتاج شبکه عصبی عمل میکند. این سیگنالها بینشهایی را در مورد فرآیندهای محاسباتی TPU ارائه میدهند و به مهاجمان اجازه میدهند تا پیکربندیهای مدل بحرانی را بدون دانش قبلی از معماری یا نرمافزار مدل استنباط کنند.
این حمله میتواند هایپرپارامترهای[2] دقیق مدل، از جمله انواع لایهها، تعداد گرهها، اندازه هسته، گامها و توابع فعالسازی را استخراج کند. این سطح از جزئیات، مهاجمان را قادر میسازد تا کل مدل هوش مصنوعی را بازسازی کنند، که خطرات قابل توجهی برای سرقت مالکیت معنوی و حملات سایبری احتمالی به دنبال دارد.
در حالی که این حمله بسیار موثر است، نیازمند دسترسی فیزیکی به TPU هدف و تجهیزات تخصصی و گران قیمت برای گرفتن سیگنالهای EM است. این محدودیت به این معناست که مهاجمان باید در طول عملیات در نزدیکی دستگاه باشند. این حمله، تهدید قابل توجهی برای سیستمهای هوش مصنوعی مستقر در ابر به شمار میآید.
EPSS مستعد حملات دستکاری است
تحقیقات اخیر نشان داده است که فریمورکهای هوش مصنوعی مانند سیستم امتیازدهی پیشبینی اکسپلویت (EPSS)، ابزاری که برای ارزیابی احتمال سوءاستفاده از آسیب پذیریها استفاده میشود، در برابر دستکاری از طریق حملات تهاجمی آسیب پذیر میباشند.
این دستکاری میتواند منجر به تخصیص نادرست منابع با آسیب پذیریهایی شود که بر اساس پیش بینیهای اکسپلویت نادرست اولویت بندی شدهاند. از این رو، این یافته نگرانی هایی را در مورد قابلیت اطمینان از امتیاز EPSS در هدایت تلاش برای مدیریت آسیب پذیری سازمانها ایجاد میکند.
مدل EPSS، سیگنالهای خارجی مانند ذکر در رسانههای اجتماعی و وجود کد اکسپلویت در مخازن عمومی را به عنوان شاخصهای ریسک بهرهبرداری بالقوه ترکیب میکند. این اتکا آن را مستعد دستکاری و ایجاد تغییر میسازد، چرا که مهاجمان میتوانند به طور مصنوعی این سیگنالها را تقویت کرده تا سازمانها را در مورد فوریت رسیدگی به آسیبپذیریهای خاص گمراه کنند.
محققی از Morphisec نشان داد که با دستکاری و افزایش مصنوعی معیارهای خاص (مانند فعالیت رسانههای اجتماعی و در دسترس بودن کد عمومی) میتوان بر ارزیابی EPSS از یک آسیب پذیری خاص تأثیر گذاشت. با تولید توییتهای جعلی و ایجاد یک مخزن اکسپلویت در GitHub، احتمال بهرهبرداری پیشبینیشده برای این CVE از ۰.۱ به ۰.۱۴ افزایش یافته و رتبه آن از صدک 41 به صدک 51 منتقل شده است.
تکنیک اثبات مفهوم (PoC) نشان میدهد که یک عامل تهدید میتواند از اتکای EPSS به سیگنالهای خارجی برای تقویت معیارهای فعالیت CVEهای خاص استفاده کند، سازمانهایی که گمراهکننده هستند، روی امتیازات EPSS برای اولویتبندی تلاشهای مدیریت آسیبپذیری خود حساب میکنند.
[1] Tensor processing unit
[2] hyperparameter
منابع
مقالات پیشنهادی:
معرفی ChatGPT search، مزایا و معایب آن
کشف ۳۶ آسیب پذیری در مدلهای AI و ML منبع باز!
سوء استفاده از ChatGPT-4o در کلاهبرداری های صوتی!
شناسایی شش آسیب پذیری بحرانی در فریمورک هوش مصنوعی Ollama!
تأثیر هوش مصنوعی و دیپ فیکها بر انتخابات ریاست جمهوری ۲۰۲۴ آمریکا
ایتالیا OpenAI را به دلیل نقض حریم خصوصی داده، ۱۵ میلیون یورو جریمه کرد!
چگونگه با کلاهبرداریها و محتواهای جعلی مبتنی بر هوش مصنوعی مقابله کنیم؟
نفوذ بدافزارهای رباینده اطلاعات AMOS و Lumma به برنامههای هوش مصنوعی جعلی